Bouw je eigen machine learning model en ontdek verborgen patronen
Machine Learning (ML) staat vol in de schijnwerpers. Dat is logisch, want het verbeterpotentieel van machine learning toepassingen voor organisaties is groot. Tegelijkertijd staat de impact en uitlegbaarheid van machine learning algoritmes in het particuliere en publieke domein ter discussie. Met dashboards, rapporten en data analytics brachten we jarenlang de grote en relatief eenvoudige verbanden in gegevens aan het licht. Machine learning modellen leggen, naast die grote verbanden, nu ook de kleinere, meer subtiele, complexere patronen bloot. Maar wat is machine learning eigenlijk? En hoe bouw je een betrouwbaar en werkend machine learning model? Dit proces is arbeidsintensief, uitdagend en tijdrovend. Passionned Group adviseert de juiste machine learning tools, implementeert deze, verzorgt een cursus Machine Learning op maat en levert interim-ondersteuning.
Wat is machine learning?
In deze bijdrage geven we een heldere machine learning uitleg (machine learning betekenis), een praktische machine learning definitie, een overzicht van de beschikbare machine learning modellen en toepassingen, de belangrijkste machine learning trends, de technieken en last but not least, suggesties voor de meest geschikte basiscursus Machine Learning als opstap voor een meerdaagse training Data Science & Machine Learning.
Na verschillende definities van machine learning te hebben geanalyseerd, hebben wij onze eigen sluitende definitie geformuleerd die wij hieronder als belangrijkste take-away weggeven:
Machine learning is een verzameling van zelflerende algoritmes die in staat zijn om zelfstandig patronen te ontdekken op basis van gestructureerde en ongestructureerde data en betrouwbare voorspellingen te doen die beslissingen van organisaties ondersteunen.
Zelflerende Machine Learning algoritmes
Inmiddels is machine learning uitgegroeid tot een gangbare verzamelnaam, een koepelbegrip voor zogenoemde zelflerende algoritmes. Maar wat zijn (lerende) algoritmes eigenlijk?
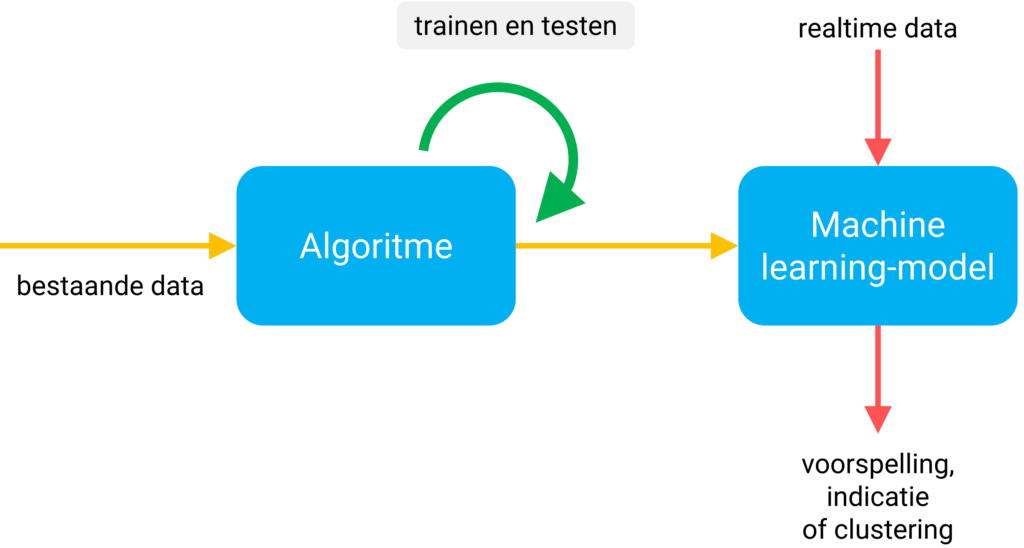
 Figuur 1: Machine learning modellen komen tot stand door ze te trainen met algoritmes. Dit zijn zelflerende computerprogramma’s die het optimale eindresultaat bewaren in een machine learning model.
Figuur 1: Machine learning modellen komen tot stand door ze te trainen met algoritmes. Dit zijn zelflerende computerprogramma’s die het optimale eindresultaat bewaren in een machine learning model.
Machine learning neemt een hoge vlucht omdat bedrijven en instellingen over steeds meer machine learning data kunnen beschikken. Om deze door big data en machine learning gedomineerde digitale samenleving te begrijpen is een heldere machine learning definitie op deze plaats dan ook onmisbaar.
Enkele machine learning definities
Machine learning is oorspronkelijk in de jaren vijftig van de vorige eeuw gedefinieerd als “een vakgebied dat computeralgoritmes laat leren zonder dat je ze expliciet hoeft te programmeren” (Samuel, 1959). Een andere gangbare definitie is de volgende: “Machine Learning is de studie van computeralgoritmes waarmee computerprogramma’s automatisch kunnen verbeteren door ervaring.” (Mitchell, 1997).
Beide machine learning definities klinken misschien wat gedateerd en statisch in de oren, maar doen in essentie wel recht aan het zelflerende karakter dat zo kenmerkend is voor zowel de oudere en zeker voor de moderne geavanceerde algoritmes. Algoritmes veranderen en zijn in staat zichzelf voortdurend te ontwikkelen. Feitelijk is machine learning een dynamisch leerproces: de algoritmes leren door patronen te herkennen in de data.
Volgens een van de grootste softwarebedrijven ter wereld is machine learning (ML) een vorm van kunstmatige intelligentie (AI) die is gericht op het bouwen van systemen die van de verwerkte data kunnen leren of data gebruiken om beter te presteren. Deze definitie is praktisch, dynamisch, prestatiegericht en benadrukt ook het lerende karakter, maar mist alleen nog de voorspellende vermogens van algoritmes.
Big data, data science, machine learning en deep learning worden vaak in één adem genoemd. Hetzelfde geldt voor data analytics en machine learning. Door al deze begrippen echter op één hoop te gooien, zonder de verschillen en/of overeenkomsten tussen AI, data science, machine learning en BI aan te geven, ontstaat er al snel verwarring.
Wat is de overeenkomst tussen BI en machine learning?
De overeenkomst tussen machine learning en Business Intelligence is dat beide vakgebieden intensief gebruikmaken van data. BI is het continue proces waarmee organisaties op gerichte wijze big data verzamelen en registreren, combineren, analyseren en visualiseren. Het gaat dan met name om rapporten, dashboards en eenvoudige data analyses. Het doel is om de daaruit resulterende (voorspellende) informatie en kennis consequent te gebruiken om betere beslissingen te nemen. Machine learning algoritmes hebben diezelfde focus, maar graven veel dieper in de data en zijn in staat om ook de complexere patronen te ontdekken die voor het menselijk oog onzichtbaar blijven. De senior consultants van Passionned Group zijn in staat om dat soort algoritmes te bouwen en met succes te implementeren.
Het handboek Artificial Intelligence Machine learning en algoritmes komen uitgebreid aan bod in deze geheel nieuwe druk van het AI boek 'De intelligente, datagedreven organisatie'. Leer hoe deze krachtige technieken kunnen bijdragen aan een meer intelligente en slagvaardige organisatie die sneller en betere beslissingen neemt. Al meer dan 25.000 exemplaren verkocht.
Machine learning en algoritmes komen uitgebreid aan bod in deze geheel nieuwe druk van het AI boek 'De intelligente, datagedreven organisatie'. Leer hoe deze krachtige technieken kunnen bijdragen aan een meer intelligente en slagvaardige organisatie die sneller en betere beslissingen neemt. Al meer dan 25.000 exemplaren verkocht.
Wat is het verschil tussen machine learning en AI?
Artificial intelligence is het overkoepelende vakgebied dat zich bezighoudt met het ontwikkelen van intelligentie buiten het menselijk brein. Machine learning daarentegen is een specialistisch onderdeel van AI dat zich bezig houdt met het ontwikkelen van zelflerende algoritmes en technieken die softwaresystemen in staat stellen zelfstandig te leren.
Wat is het verschil tussen data science & machine learning?
Het verschil tussen data science en machine learning laat zich als volgt verklaren. Data science, of letterlijk vertaald datawetenschappen, is volgens Wikipedia een interdisciplinair onderzoeksveld dat wetenschappelijke methoden, processen en systemen gebruikt om kennis en inzichten te onttrekken uit zowel gestructureerde als ongestructureerde data. In die zin kun je data science en BI aan elkaar gelijkschakelen. Maar datawetenschap maakt onder meer gebruik van de subdomeinen van machine learning, zoals classificatie, cluster-analyse, datamining, databases, en datavisualisatie.
Wat is de link tussen machine learning en data analytics?
Data analytics is het vakgebied dat zich bezig houdt met het analyseren van grote hoeveelheden data binnen organisaties. Met machine learning data analytics kun je organisatiebeslissingen beter onderbouwen. Binnen het vakgebied van data analytics zijn vier hoofdstromen te onderscheiden: descriptive (beschrijvend), diagnostic (verklarend), predictive (voorspellend) en prescriptive analytics (voorschrijvend). Machine learning houdt zich in deze context vooral bezig met predictive analytics, oftewel voorspellingen.
TIP: laat de definities rustig op je inwerken, maar onthoud ondertussen dit rijtje van data scientist David Robinson (2017): data science levert inzichten, machine learning levert voorspellingen en artificial intelligence levert richtlijnen voor autonome acties.
Belangrijkste kenmerken van machine learning modellen
Machine learning modellen kun je herkennen aan een aantal gemeenschappelijke kenmerken. De belangrijkste kenmerken vatten we hier samen:
- er is sprake van een grotere verzameling data met veel verschillende kenmerken, oftewel big data
- het ontdekken van complexe verbanden en patronen die voor een mens vaak niet (in 1 oogopslag) zichtbaar zijn
- de probleemstelling staat van tevoren vast, de data die daarbij nodig is niet
- soms is de doelvariabele bekend (supervised) en soms ook niet (unsupervised)
- goede machine learning modellen zijn reken- en kennisintensief
3 verschillende soorten machine learning modellen
Machine learning modellen kun je in drie verschillende categorieën indelen aan de hand van het leerproces dat zelflerende algoritmes doormaken. Machine learning kent aldus drie hoofdcategorieën.
Supervised learning
Er is sprake van supervised learning wanneer het algoritme leert onder supervisie van een leraar of expert. Deze labelt of tagt de inputdata en hij vertelt het algoritme naar welke doelvariabele het op zoek moet gaan. Hij verklapt van tevoren het juiste antwoord.
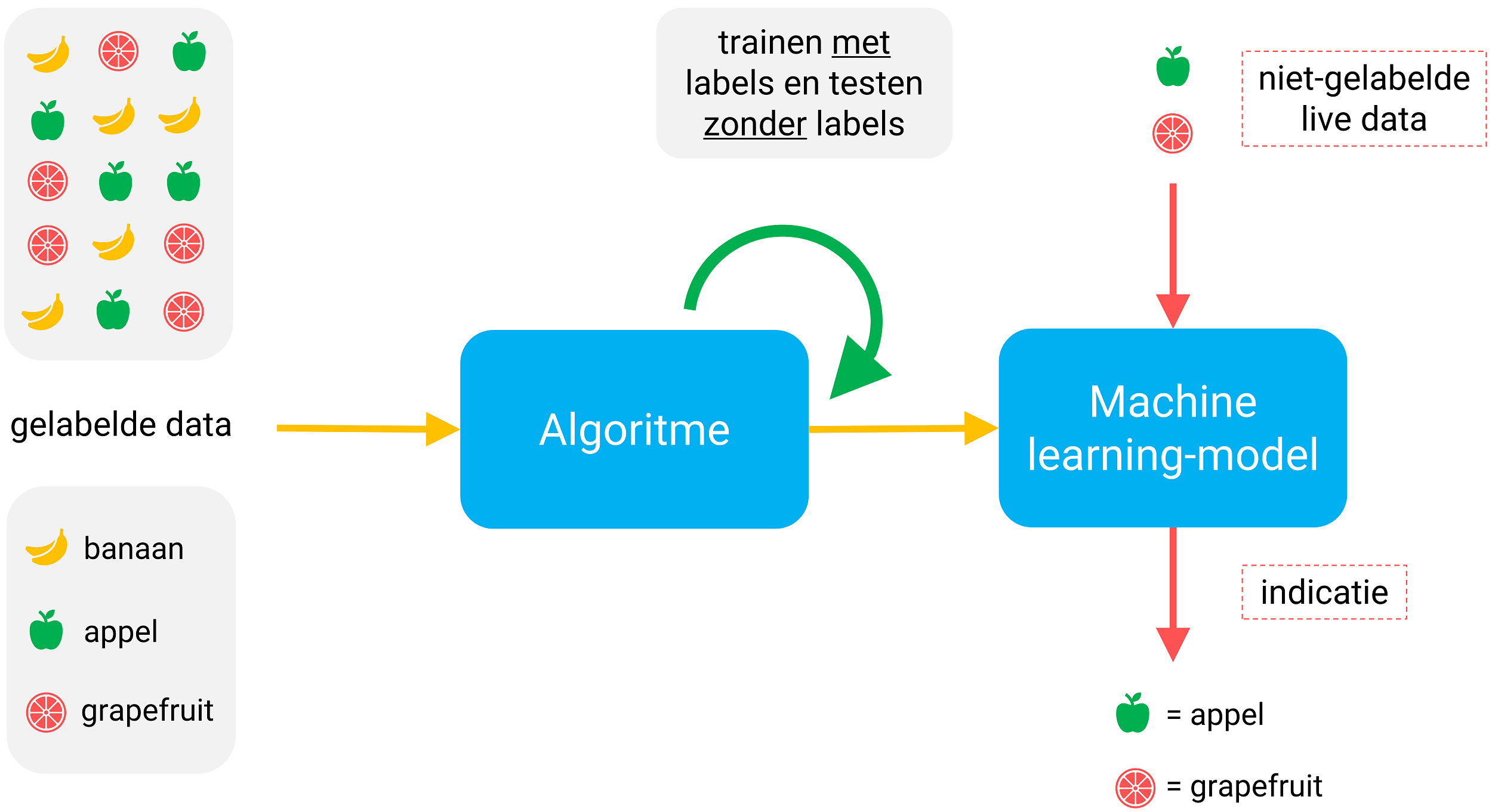
Figuur 2: Een schematische weergave van een supervised learning proces om fruit te herkennen.
Bij een classificatie van bijvoorbeeld vakantiefoto’s geeft de supervisor bijvoorbeeld aan op welke foto’s een kerk staat en op welke foto’s geen kerk staat. Langzaamaan gaat het algoritme de foto’s met kerken herkennen. Dit houd je net zo lang vol totdat je vindt dat het algoritme voldoende getraind is en hoge scores behaalt. Deze kennis giet je vervolgens in een machine learning model waarna het algoritme nieuwe foto’s kan gaan beoordelen, al dan niet realtime.
Unsupervised learning
Bij unsupervised learning krijgt het algoritme een set met data en gaat zelf zonder supervisie (dus zonder leraar of expert) op zoek naar associaties, categorieën en clusters. Je geeft geen doelvariabele mee. Het algoritme probeert automatisch structuur te vinden in de dataset en kan kenmerken extraheren, bijvoorbeeld in welke buurt een huis is gelegen.

Figuur 3: Unsupervised learning zoekt zelf naar clusters of patronen. Je hoeft alleen maar de data aan te bieden.
De uitkomsten van deze categorie machine learning modellen kunnen minder voorspelbaar zijn (er is geen juist antwoord) dan bij supervised learning. Daarom is het succes van dit type algoritme vaak ook moeilijk meetbaar. Toch is de verwachting dat de volgende doorbraak in machine learning uit deze hoek zal komen.
Reinforcement learning
Bij deze vorm van machine learning stimuleer je de creativiteit van een zogenaamde “agent”, die bestaat uit een algoritme of een reeks algoritmes die elk afzonderlijk specifieke taken uitvoeren, of als geheel een taak hebben meegekregen. De agent krijgt van de ontwerper alleen de regels van het spel mee. Door middel van slimme trial-and-error acties (leren van fouten) zoekt de agent binnen de data machine learning berg een weg naar een oplossing. Er zijn immers meer wegen die naar Rome leiden.
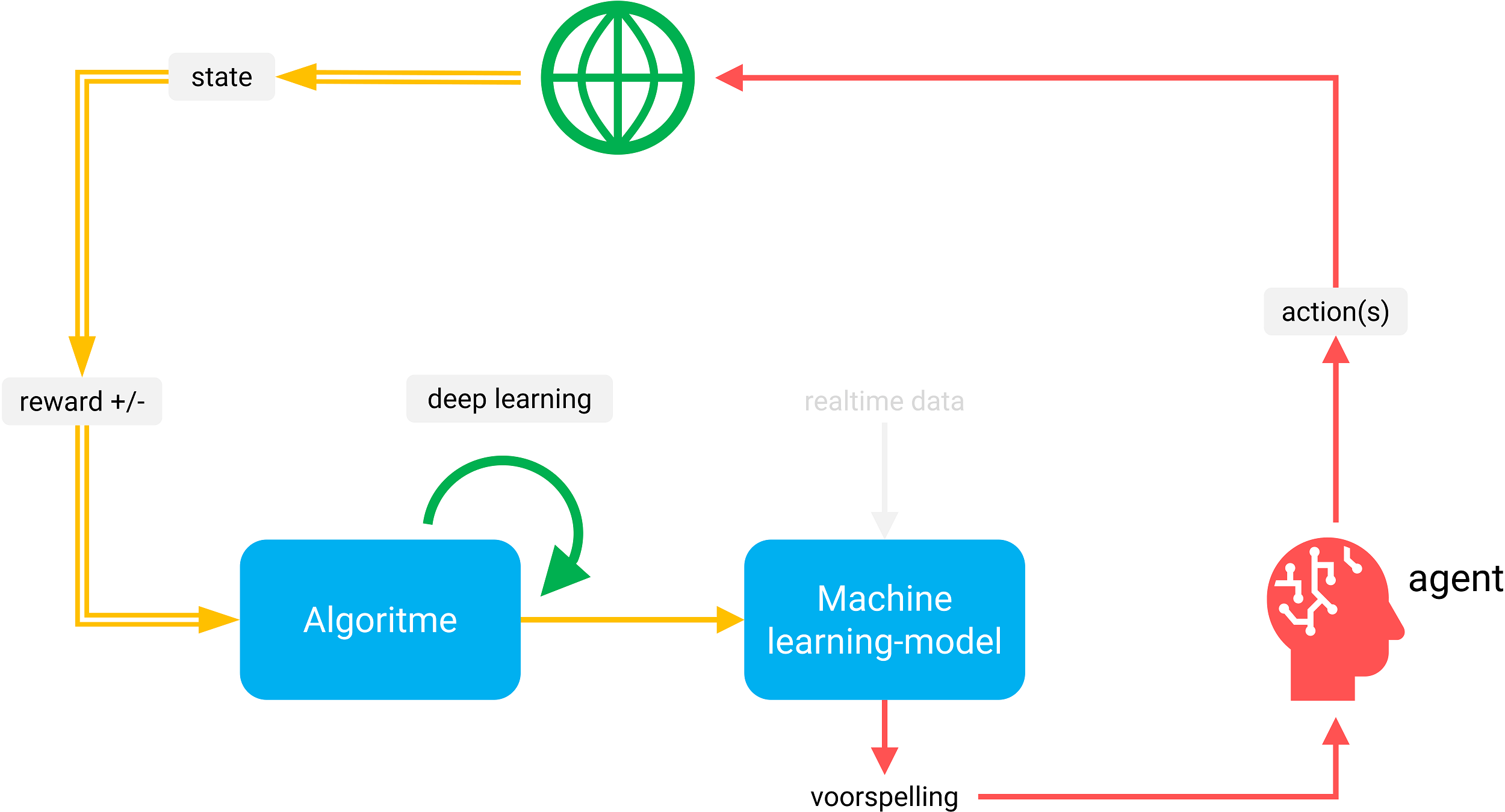
Figuur 4: Met reinforcement learning combineer je in één omgeving de data, een machine learning model, decision making en acties. Hiermee ontwerp en bouw je een complete, zelflerende en krachtige feedback-loop.
Wanneer een stuk van de juiste weg is ingeslagen, krijgt het algoritme een “beloning”, bij het nemen van een onvoordelige afslag krijgt het “straf”. Deze vorm van machine learning wordt inmiddels veelvuldig toegepast in zelfrijdende auto’s die het optimum in elke specifieke situatie moeten zien te vinden tussen snelheid, veiligheid en rijcomfort. Maar ook bij het besturen van de armen en benen van een robot.
Naast supervised en unsupervised learning, bestaat er ook nog een hybride tussenvorm: semi-supervised learning. Deze manier van leren combineert supervised met unsupervised learning. Wil jij ook aan de slag met (un)supervised learning modellen of reinforcement learning? Neem dan hier contact met ons op of bestel het Artificial Intelligence-handboek.
Verschil deep learning en machine learning
Deep learning is een subcategorie binnen de machine learning modellen. Bij toepassing van deep learning wordt getracht de werking van het menselijk brein na te bootsen. De term “deep” verwijst naar het aantal lagen in het neurale netwerk, oftewel de diepte van het neurale netwerk. Kunstmatige neurale netwerken zijn daarmee complementair aan en geïnspireerd op de biologische neurale netwerken binnen het menselijke brein.
De toepassingen van deep learning zijn divers. Ze worden succesvol ingezet op het gebied van bijvoorbeeld beeld- en spraakherkenning, bij vertaalopdrachten of de beoordeling van medische scans. Zo is een deep learning algoritme in staat om verschillende vormen van dementie vroegtijdig te herkennen.
10 populaire machine learning toepassingen
Een model machine learning zet je in om kritieke bedrijfsbeslissingen in marketing, operations, HR, financiën en verkoop te ondersteunen en te verbeteren. Ook worden machine learning toepassingen in het algemeen ingezet om de klantrelatie te verbeteren, afnamepatronen te voorspellen, wachttijden te verminderen of om maatschappelijke processen in het publieke domein te verbeteren. Hieronder geven we ter illustratie vijf concrete toepassingen van machine learning in business situaties en vijf voorbeelden machine learning afkomstig uit het publieke domein.

- Recommendations (aanbevelingen). Bekend zijn de algoritmegedreven filmsuggesties op Netflix, koopaanbevelingen op Amazon, vriendensuggesties op Facebook of contactvoorstellen op LinkedIn. Maar ook webshops maken intensief gebruik van machine learning voor productpersonalisatie, contextuele zoekresultaten, chatbots, virtuele assistenten en kunstmatig gegenereerde fotomodellen.
- Onregelmatigheidsdetectie. Bij deze vorm van machine learning ga je je richten op de uitzonderingen in de brede zin van het woord. Zo kun je bijvoorbeeld met onregelmatigheidsdetectie fraude detecteren of spamberichten in e-mailboxen filteren. Je zoekt dan juist naar statistische onregelmatigheden in je data. De zogenaamde outliers.
- Dynamische beprijzing. Bij dynamische prijsstelling variëren de machine learning algoritmes automatisch de prijs. Die prijs is onder meer afhankelijk van de prijzen bij de concurrent, het tijdstip van de dag, de week of maand, de vraag én het beschikbare aanbod. Dynamic pricing wordt veelvuldig toegepast in de toeristenindustrie door onder meer vliegtuigmaatschappijen, hotelkamers enzovoorts.
- Voorspellend onderhoud (predictive maintenance). Voorspellend onderhoud en machine learning is een van de meest rationele en aansprekende machine learning toepassingen. Het voorkomt ongeplande downtime van dure machines en installaties in de industrie, in de maritieme sector, binnen de sector weg- en waterbouw, de energiesector, de olie- en gassector, enzovoorts. Ook bespaar je op onnodig onderhoud, want je doet het precies op het juiste moment.
- Process mining. Bij process mining machine learning worden gespecialiseerde algoritmes, zoals de exotisch klinkende alpha miner, fuzzy miner, heuristics, transition system miners en genetische algoritmes, toegepast op data van event logs. Het doel is om procesafwijkingen te ontdekken en toekomstige processen beter te voorspellen door deze te simuleren met machine learning software. Lees hier meer over process mining.
- Ordehandhaving. In het publieke domein gebruikt de politie cameratoezicht en machine learning data, zoals de data van intelligente camera’s en microfoons, om misdrijven in realtime op te sporen en criminaliteitshaarden (de zogenoemde hotspots) in kaart te brengen en te voorspellen waar en wanneer criminaliteit optreedt (predictive policing). Denk hierbij ook aan automatische herkenning van chauffeurs met een telefoon in de hand met behulp van deep learning.
- Filebestrijding. Adaptive signal control is een systeem om stoplichten automatisch aan te passen aan de hand van de verkeersdrukte. De technologie werkt op basis van klassieke machine learning algoritmes. Daarnaast experimenteren verschillende gemeenten in het kader van het smart city concept met slimme lantaarnpalen en zebrapaden die oplichten. Het concept is uitgerust met 5G-technologie, sensoren, laadpalen en lichtscenario’s.
- Algoritmische beschikkingen. Alle ministeries, bestuursorganen en uitvoeringsorganisaties maken in meer of mindere mate gebruik van algoritmes en machine learning applicaties voor hun beschikkingen. Sommige wettelijke regelingen kunnen zelfs alleen nog worden uitgevoerd met behulp van de toepassing van beslisregels op data. Dat geldt vooral voor de uitvoeringsorganen die financiële regelingen uitvoeren, zoals de Belastingdienst als het gaat om onroerendezaakbelasting, de WOZ-bepaling of de motorrijtuigbelasting. Maar denk ook aan het automatisch registreren van verkeersovertredingen (bijvoorbeeld mobiel bellen in de auto) en het automatisch afhandelen van verkeersboetes door het Centraal Justitieel Incasso Bureau.
- Robotrechtspraak. Met machine learning kun je online zoeken in jurisprudentie en hierin patronen ontdekken. Het is wellicht ooit een opstap naar een robotrechter die volledig geautomatiseerd vonnis wijst. Omdat het voor procespartijen lastig is om inzicht te krijgen in de werking van het algoritme, zal dit vooralsnog toekomstmuziek blijven. Wél wordt in de VS geëxperimenteerd met machine learning software die de kans op recidive inschat bij vrijlating van een gevangene of verdachte op borgtocht.
- Gerobotiseerde dienstverlening. Gemeenten zetten zowel fysieke robots als chatbots in om de dienstverlening aan burgers te verbeteren. Zo verlicht Robotic Process Automation (RPA) de administratieve werkdruk van gemeenteambtenaren en wijzen fysieke robots in gemeentehuizen burgers de weg. RPA en machine learning zijn voor elkaar gemaakt.
De lijst is zeker niet compleet. Ben je benieuwd naar de mogelijke machine learning data science toepassingen in jouw sector, of ben je geïnteresseerd in de exploitatie van een eigen machine learning business model, neemt dan contact met ons op.
De Python cursus Machine Learning Na het volgen van deze 3-daagse opleiding beheers je de basisbeginselen van Machine Learning en het programmeren in Python. Je hebt in teamverband diverse voorspellende modellen gemaakt die je direct in de praktijk kan toepassen. Hierdoor beschik je over een realistisch beeld van de bedrijfsproblemen die je met machine learning kunt oplossen.
Na het volgen van deze 3-daagse opleiding beheers je de basisbeginselen van Machine Learning en het programmeren in Python. Je hebt in teamverband diverse voorspellende modellen gemaakt die je direct in de praktijk kan toepassen. Hierdoor beschik je over een realistisch beeld van de bedrijfsproblemen die je met machine learning kunt oplossen.Hoe werkt machine learning: een 8 stappenplan
Bij het bouwen, implementeren, trainen, testen, finetunen, evalueren en het in productienemen van machine learning modellen, zoals een voorspellend model, komt heel wat kijken. In onderstaand stappenplan hebben we de belangrijkste acht processtappen voor je samengevat. Dit praktische stappenplan is gebaseerd op de jarenlange ervaringen van onze data scientists bij klanten in diverse sectoren.
Het stappenplan is niet in beton gegoten, maar is meer bedoeld als een checklist om te controleren of je geen cruciale stappen hebt overgeslagen. Twijfel je over de juiste aanpak of heb je detailvragen, neemt dan direct contact op met een van onze data science specialisten.
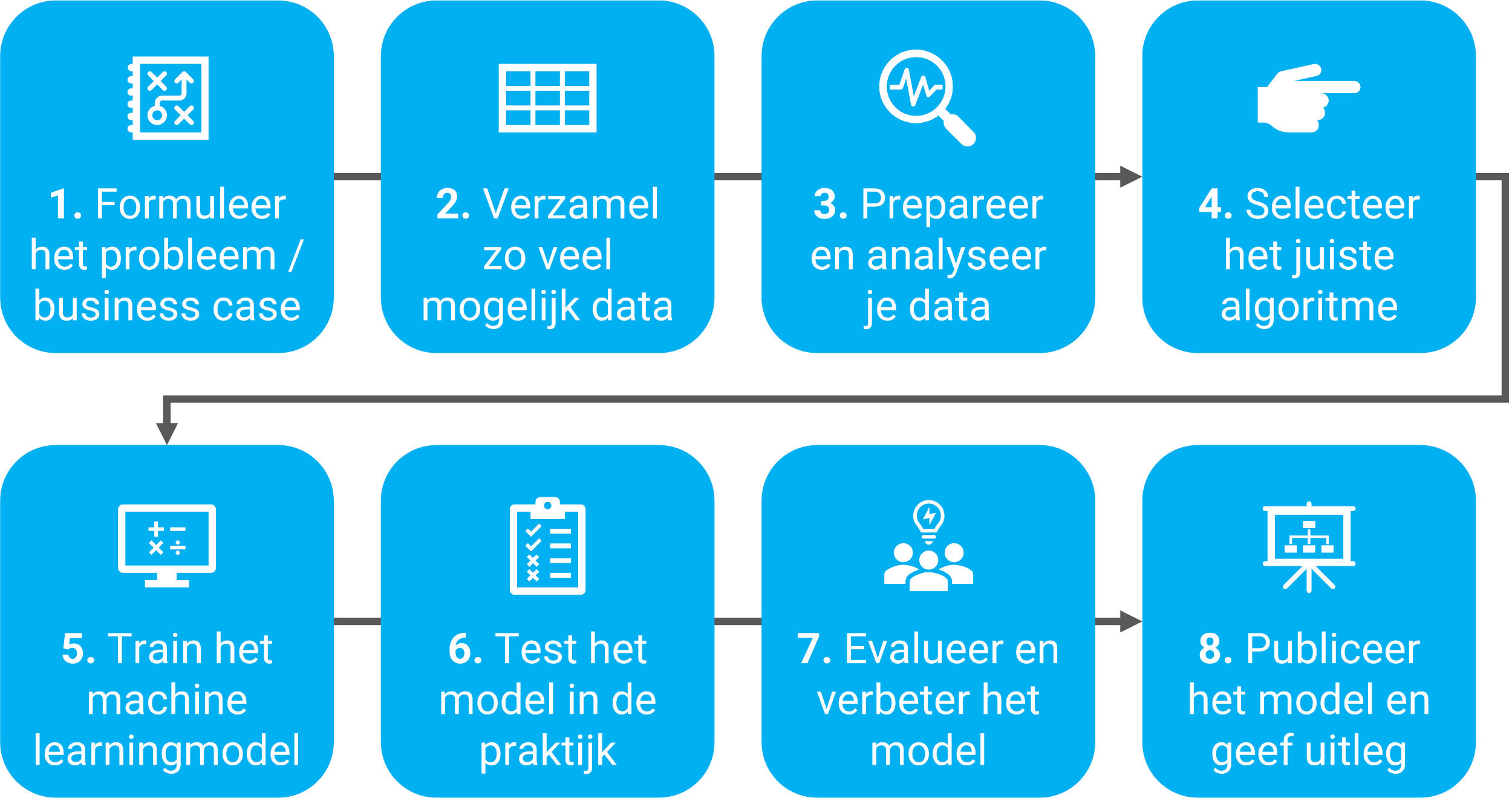
Figuur 5: Een stappenplan om machine learning modellen te ontwikkelen en in productie te nemen.
- Formuleer een heldere probleemstelling of business case. Doe dit bij voorkeur in de vorm van een onderzoeksvraag, bijvoorbeeld: hoe gaan de prijzen van computerchips zich de komende twee jaar ontwikkelen? En welke verklarende variabelen spelen hierbij een rol? Een ander voorbeeld: hoe snel verspreidt een (verkoudheids)virus zich over bepaalde werelddelen, landen en regio’s? Of: hoe kan een woningcorporatie het noodzakelijke onderhoud aan woningen voorspellen en inplannen?
- Verzamel zoveel mogelijk historische data over de onderzoeksvraag. Beperk je niet alleen tot de interne bedrijfsgegevens, maar betrek ook externe dataleveranciers bij de dataverzameling, zoals het CBS, de Kamers van Koophandel, brancheorganisaties enzovoorts. Raadpleeg zoveel mogelijk uiteenlopende in- en externe bronnen om een zo representatief mogelijke dataverzameling op te bouwen. Vraag jezelf af welke data je eventueel nog mist. Hiermee voorkom je in deze cruciale fase mogelijk al biasses in het te bouwen machine learning model.
- Prepareer je data en maak deze geschikt voor modelmatige toepassing. Voordat je de verzamelde data kunt gebruiken voor machine learning zul je de ruwe data moeten omwerken tot trainingsdata (data modelleren). Data en bestanden worden genoteerd in verschillende formats en extensies. Verder valt er meestal nog veel af te dingen op de integriteit, consistentie en logica van data. Om de verzamelde data op één noemer te krijgen is er dus een bewerkingsslag (data cleaning) noodzakelijk. Zo transformeer je de ruwe data tot trainingsdata.
- Kies het juiste algoritme. Het kiezen en het optimaliseren van het juiste algoritme of een ensemble van algoritmes voor jouw onderzoeksvraag of businesscase is lastig, zeker voor leken. Algoritmes worden ingedeeld in verschillende categorieën, ook wel families genoemd, zoals aanbevelingssystemen, classificatiesystemen, clustering, anomaliedetectie, regressiemodellen en tekstanalyses. Elk algoritme is ontworpen om een ander type onderzoeksvraag op te lossen. Toch kan het lonen om verschillende soorten algoritmes met elkaar te laten concurreren om uiteindelijk via trial & error tot optimale voorspellingsresultaten te komen.
- Train het machine learning model. Dankzij het opschonen van de ruwe data kun je nu met je trainingsdata aan de slag. Een gebruikelijke manier om modellen te trainen, is om hierbij een trainingsscript te gebruiken. Tijdens dit trainingsproces krijgt een algoritme de trainingsdata aangeboden en zoekt het zelfstandig naar een manier om tot een correct antwoord of oplossing te komen. Er is met andere woorden sprake van een input-output model.
- Test het machine learning model in de praktijk. Om er zeker van te zijn dat het machine learning model correct voorspelt, moet het getest worden. Een tweede afgesplitste test dataset wordt daarom gebruikt om de werking en nauwkeurigheid van het model te controleren: hoe nauwkeurig kan het model de uitkomst voorspellen? Er kan zowel sprake zijn van overfitting als underfitting, waardoor het model de uitkomsten minder nauwkeurig voorspelt dan verwacht. Accepteer geen slechte uitkomst. Beter ten halve gekeerd dan ten hele gedwaald.
- Evalueer en verbeter het machine learning model. Nadat de nauwkeurigheid is berekend, kun je in deze stap verdere verbeteringen in het model doorvoeren. Maak hierbij gebruik van bewezen statistische technieken zoals kruisvalidering (K-voudige kruisvalidatie) om de prestaties van de algoritmes te evalueren. Hierbij splits je de trainingsdata op in een aantal subsets van de totale datasets. Je gebruikt deze subsets (“folds”) vervolgens om het model te trainen en je valideert met de overgebleven folds. Dit herhaal je een aantal keer (K-voudig). Uiteindelijk ga je de prestaties van jouw machine learning model testen en vergelijken met de uiteindelijke testdata.
- Publiceer het machine learning model en leg het uit. Nadat je je machine learning model hebt getraind, getest, geëvalueerd en verbeterd hebt, is het tijd voor de uitrol naar een acceptatie- en productieomgeving. Dan pas ervaar je eer van je werk. Vergeet hierbij vooral niet uit te leggen hoe het algoritme (globaal) tot stand is gekomen. Voor veel niet-wiskundig opgeleide collega’s is een machine learning model waarschijnlijk een black box die ze met enige argwaan zullen begroeten.
Over- en underfitting van machine learning modellen
De juiste afstemming van machine learning modellen luistert nogal nauw. Er kan zowel sprake zijn van overfitting als underfitting. Beide fenomenen zorgen ervoor dat het machine learning model suboptimaal functioneert en niet de gewenste betrouwbare voorspellingen oplevert.
 Figuur 6: Overfitting en underfitting geïllustreerd voor regressie- en classificatiemodellen.
Figuur 6: Overfitting en underfitting geïllustreerd voor regressie- en classificatiemodellen.
 Figuur 7: Ergens halverwege bevindt zich een “sweet spot” waarbij de uitkomsten van het machine learning model het meest betrouwbaar zijn.
Figuur 7: Ergens halverwege bevindt zich een “sweet spot” waarbij de uitkomsten van het machine learning model het meest betrouwbaar zijn.
Bij overfitting en underfitting is het machine learning-model prima in staat om op basis van de trainingsdataset een correcte en zelfs zeer nauwkeurige voorspelling of classificatie te maken. Wanneer het echter wordt losgelaten op een testdataset of werkelijke data, gaat het volledig de mist in:
- Overfitting. Het algoritme leerde verbanden te zien op basis van de trainingsdataset, maar in nieuwe data zijn die er helemaal niet. Dit duidt op overfitting of overtraining. Het model is te specifiek gemaakt. Het bevat te veel parameters en kan daardoor niet goed generaliseren of afwijken van eerder gevonden patronen. Het model “onthoudt” de trainingsdata, bijvoorbeeld wanneer er evenveel parameters zijn als observaties, in plaats van dat het heeft geleerd te generaliseren. Een manier om overfitting te voorkomen, is door het algoritme te voeden en te trainen met meer (diverse) gegevens.
- Underfitting. Bij underfitting is het machine learning model te generalistisch. Het bevat te weinig diversiteit en kan het niet goed specificeren. Bij overfitting kun je hier nog een mouw aan passen door handmatig parameters te elimineren. Bij underfitting zou je de trainingsperiode van het algoritme kunnen verlengen.
Wil jij hulp bij het optimaliseren van je machine learning model? Schakel dan een van de machine learning experts in van de Passionned Group.
Maak vaart met machine learning dankzij AutoML
De meest opvallende ontwikkeling op het terrein van machine learning tools is de opmars van Auto ML. Naast Google biedt ook Microsoft deze machine learning tool vanuit zijn cloud aan via het Microsoft Azure Platform. Daarnaast zijn er enkele tientallen grotere en kleinere softwareleveranciers actief op de markt die platformen en machine learning tools voor AutoML aanbieden.
Wat is geautomatiseerde machine learning (AutoML)?
Geautomatiseerde machine learning, meestal afgekort tot AutoML, is eigenlijk een doe-het-zelf pakket voor het bouwen van je eigen machine learning model. Het handmatig ontwikkelen van een machine learning model is tijdrovend omdat een aantal stappen en taken herhaaldelijk terugkomen. Ook het vergelijken van tientallen modellen en algoritmes vergt in de praktijk heel veel tijd en diepgaande domeinkennis. AutoML automatiseert dat proces grotendeels, waardoor je als gebruiker eindeloos kunt experimenteren met de verschillende soorten parameters en algoritmes. Ook kun je het machine learning model iteratief trainen, totdat het machine learning model klaar is voor productie. Kun je nu met AutoML machine learning helemaal overlaten aan leken? Verre van dat, want machine learning is en blijft een echt vak. Een wiskundig georiënteerde studie die niet voor niets aan universiteiten en opleidingsacademies, zoals Passionned Academy, wordt onderwezen en een zekere basiskennis veronderstelt.
Voordelen AutoML
Het zijn nu nog met name de ervaren gegevenswetenschappers, data analisten en ontwikkelaars die kunnen profiteren van automated machine learning management. Maar ook niet-experts kunnen in de toekomst wellicht gebruikmaken van machine learning modellen en technieken. Dit is een grote verschuiving in de manier waarop we tot nu toe machine learning inzetten. AutoML toont de gebruiker een waaier aan keuzes, zoals de selectie van een trainingsdataset, het kiezen van een type algoritme, het trainen van het model en de wijze waarop hij het model kan toepassen. Op basis van het getrainde model gaat AutoML bijvoorbeeld op basis van de data in het dashboard of rapport zelf op zoek naar interessante verbanden en presenteert die aan de gebruiker. Het AutoML-systeem presenteert ook een rapport hoe de verschillende door de gebruiker gekozen machine learning modellen presteren. AutoML kan als losstaande machine learning tool voorkomen, maar ook als component binnen data discovery tools.
Machine learning trends 2026
Naast de hierboven genoemde megatrend van AutoML hebben we voor jou de volgende machine learning trends verzameld. We stippen ze hier slechts kort aan. Heb je vragen of wil je meer informatie over onze training Machine Learning, neem dan nu contact met ons op.

- De roep om wet- en regelgeving zoals het opzetten van een Nationaal Algoritme Register dat een effectieve vergelijking en beoordeling van machine learning initiatieven en algoritmes mogelijk moet maken, zal steeds luider klinken.
- Er zullen steeds meer stemmen opgaan om een keurmerk voor algoritmes in te voeren, of nog extremer een zogenoemde “data kill” knop. Dit met het oog op de gewenste transparantie van machine learning en uitlegbaarheid van algoritmes.
- De overheid zal proberen de zogenoemde brain drain van machine learning onderzoekers en experts te stoppen door de (arbeids)omstandigheden voor hen te verbeteren.
- Door de opmars van het Internet of Things en de embedded microcontrollers ontstaat een nieuwe subcategorie van machine learning modellen: TinyML, waarmee je sensordata kunt analyseren op apparaten met een extreem laag stroomverbruik.
- Zogenoemde Generative Adversarial Networks (GAN-systemen) produceren nieuwe content zoals bijvoorbeeld niet bestaande gezichten, menselijke stemmen, teksten, nieuwsberichten en audio opnames. Overheden zullen proberen de schaduwkant van GANs, de zogenoemde deep fakes, de kop in te drukken.
Passionned Group is dankzij haar omvangrijke netwerk in staat om op korte termijn gekwalificeerde data scientists te leveren om jou te helpen bij het ontwikkelen en implementeren van machine learning modellen en toepassingen. Informeer naar de mogelijkheden en voorwaarden.
Machine learning technieken
Machine learning modellen maken onder andere gebruik van verschillende basistechnieken (regressie machine learning en machine learning clustering) en verschillende soorten algoritmes. De algoritmes variëren van eenvoudige functies, business rules, beslisbomen, clusteranalyses, tot en met lineaire regressie, logistische regressie, zogenoemde probabilistische of Bayesian netwerken en genetische algoritmes. Een compleet overzicht en een beschrijving van alle soorten en smaken algoritmes tref je aan in het Artificial Intelligence-boek De intelligente, datagedreven organisatie.
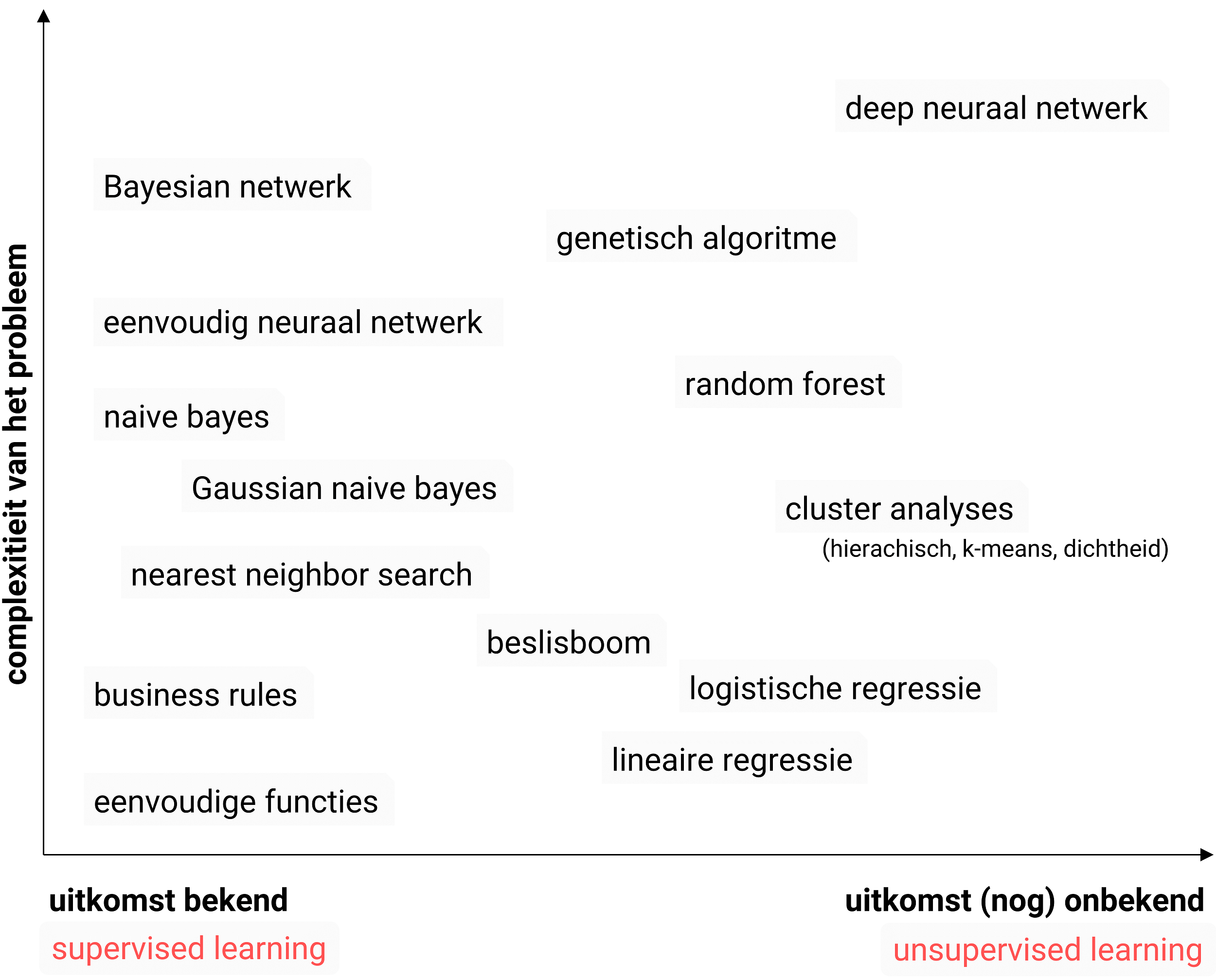
Figuur 8: De verschillende soorten machine learning technieken (smaken algoritmes)
We kunnen daarnaast nog een aantal meer generieke machine learning technieken onderscheiden zoals: datamining, textmining en natural language processing.
- Data mining is een techniek voor het vinden van verbanden, patronen en correlaties in gestructureerde data met behulp van machine learning, statistiek en databasetechnieken.
- Tekstmining is het vinden van verbanden, patronen en correlaties in ongestructureerde data zoals tekst. Ook hier is het doel om nieuwe inzichten en kennis te vergaren.
- Natural Language Processing is het vakgebied dat zich bezighoudt met het lezen, begrijpen en produceren van menselijke taal door computers.
5 machine learning tips
- Zoals Stephen Covey al adviseerde: “Begin with the end in mind”. Begin machine learning altijd met een bepaald einddoel voor ogen. Machine learning projecten hebben de hoogste kans van slagen als je je richt op een specifiek, urgent probleem dat een oplossing behoeft. Concentreer je op een probleem met impact op je bottom line. Houd een scherpe focus op die eindoplossing. KPI’s vormen daarbij de uitgelezen kans.
- Breng verschillende kennisdomeinen bij elkaar om het op te lossen probleem zo goed mogelijk te definiëren en in te kaderen. Het ontwikkelen van machine learning-modellen is arbeidsintensief, uitdagend, tijdrovend en vereist samenwerking van experts uit verschillende disciplines. Start met een eenvoudig model en temper de verwachtingen als die te hoog gespannen zijn.
- Omdat machine learning van zichzelf al zéér rekenintensief is, dien je zo min mogelijk extra bewerkingen uit te voeren. Werk je met gestructureerde data, zet dan alle benodigde data klaar in één zogenaamd “plat” bestand. Hierdoor kun je het algoritme sneller trainen en sneller met resultaten komen.
- Probeer niet zelf het wiel uit te vinden. Softwareleveranciers hebben vaak al de nodige machine learning tools, cheat sheets, programmeertalen, zoals Python machine learning en machine learning software ontwikkeld. Maak gebruik van de beschikbare platforms, kant-en-klaar bibliotheken (libraries) en van AutoML. Je hoeft dus niet zelf de tools Machine Learning te ontwikkelen.
- Vergeet niet de context van de historische trainingsdata mee te wegen. De onafhankelijke variabele die je in een machine learning model stopt kan gekleurd zijn door culturele factoren waardoor biases of vooroordelen in de trainingsdata kunnen sluipen. Discriminatie van bepaalde groepen ligt bij het definiëren van algoritmes altijd op de loer.
Huur een machine learning expert in
Het ontwikkelen van machine learning-modellen is arbeidsintensief en vereist de samenwerking van experts uit verschillende disciplines in de organisatie. Een externe machine learning specialist inhuren kan verstandig zijn om iedereen op één lijn te krijgen. Neem nu contact met ons op als je overweegt een data scientist, machine learning expert of AI consultant in te schakelen.
Volg onze cursus Machine Learning
De Python Machine Learning training van Passionned Academy speelt in op de groeiende behoefte bij (business) analisten, aankomend data scientists en andere professionals om te gaan experimenteren met AI, data science, machine learning, algoritmes en alles wat daarmee samenhangt. Na het volgen van onze Machine Learning Python training beheers je de basisbeginselen van machine learning en het programmeren in Python. Bovendien weet je welke bedrijfsproblemen je met machine learning kunt oplossen. Schrijf je nu in voor deze cursus Machine Learning met Python of onze Machine Learning Big Data course.
Meer informatie
Technische boeken over machine learning zijn er in overvloed. Maar ben je op zoek naar een praktisch boek waarin machine learning modellen en algoritmes op een laagdrempelige, begrijpelijke manier worden uitgelegd, dan is ons Artificial Intelligence boek ‘De intelligente, datagedreven organisatie’ een absolute aanrader. Bestel het boek nu of volg onze Machine Learning cursus als opstap naar een master of science in Machine Learning. Wil je advies, neem contact met ons op.

